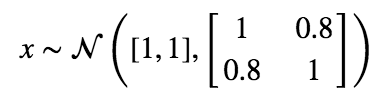If you haven’t yet discovered the competitive machine learning site kaggle.com, please do so now. I’ll wait.
Great – so, you checked it out, fell in love and have made it back. I recently downloaded the data for the getting started competition. It consists of 42000 labelled images (28×28) of hand written digits 0-9. The competition is a straight forward supervised learning problem of OCR (Optical Character Recognition). There are two sample R scripts on the site to get you started. They implement the k-nearest neighbours and Random Forest algorithms.
I wanted to get started by visualizing all of the training data by rendering some sort of an average of each character. Visualizing the data is a great first step to developing a model. Here’s how I did it:
## Read in data
train <- read.csv("../data/train.csv", header=TRUE)
train<-as.matrix(train)
##Color ramp def.
colors<-c('white','black')
cus_col<-colorRampPalette(colors=colors)
## Plot the average image of each digit
par(mfrow=c(4,3),pty='s',mar=c(1,1,1,1),xaxt='n',yaxt='n')
all_img<-array(dim=c(10,28*28))
for(di in 0:9)
{
print(di)
all_img[di+1,]<-apply(train[train[,1]==di,-1],2,sum)
all_img[di+1,]<-all_img[di+1,]/max(all_img[di+1,])*255
z<-array(all_img[di+1,],dim=c(28,28))
z<-z[,28:1] ##right side up
image(1:28,1:28,z,main=di,col=cus_col(256))
}
Which gives you:
 Notice the wobbly looking ‘1’. You can see that there is some variance in the angle of the slant, with a tenancy toward leaning right. I imagine that this is due to the bias toward right handed individuals in the sample.
Notice the wobbly looking ‘1’. You can see that there is some variance in the angle of the slant, with a tenancy toward leaning right. I imagine that this is due to the bias toward right handed individuals in the sample.
I also wanted to generate a pdf plot of all of the training set, to get myself an idea of what kind of anomalous instances I should expect.
If you are interested, dear reader, here is my code to do just that.
pdf('train_letters.pdf')
par(mfrow=c(4,4),pty='s',mar=c(3,3,3,3),xaxt='n',yaxt='n')
for(i in 1:nrow(train))
{
z<-array(train[i,-1],dim=c(28,28))
z<-z[,28:1] ##right side up
image(1:28,1:28,z,main=train[i,1],col=cus_col(256))
print(i)
}
dev.off()
Which will give you a 2625 page pdf of every character in the training set which you can, um, casually peruse.
 As of the time of writing, the current leading submission has a classification accuracy of 99.27%. There is no cash for this competition, but the knowledge gained from taking a stab at it is priceless. So give it a shot!
As of the time of writing, the current leading submission has a classification accuracy of 99.27%. There is no cash for this competition, but the knowledge gained from taking a stab at it is priceless. So give it a shot!