I’ve been showing my new favourite toys to just about anyone foolish enough to actually engage me in conversation. I described how my shiny new set of non-transitive dice work here, complete with a map showing all the relevant probabilities.
All was neat and tidy and wonderful until fellow ecologist, Aaron Ball, tried to burst my bubble.
Nope. I couldn’t find the error. Fortunately, he works across the hall so I just went and asked him.
The problem he found, it turns out, was not with my calculations but with my assumptions. Aaron told me that dice constructed with rounded corners and hollowed out pips for the numbers on the faces tend to be biased in the frequency at which each face rolls up. I had assumed, of course, that each side of each of the five dice would roll with the same probability (ie. 1 in 6).
As with any model of a real world system, the mathematics were carried out on a simplified abstraction of the system being modelled. There are always, by necessity, assumptions being made. The important thing is to make these assumptions as explicit as possible and, where possible, to test the robustness of the model predictions to violations of the assumptions. Implicit to my calculations of the odds of the non-transitive Grime dice was the assumption that the dice are fair.
To check the model for robustness to this assumption, we can relax it and find out if we still get the same behaviour. Specifically, we can ask here whether some sort of pip-and-rounded-corner-induced bias can lead to a change in the Grime dice non-transitive cycles.
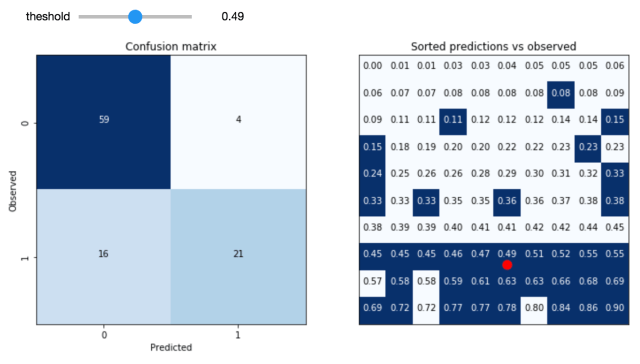
It seems a natural place to look would be between the dice pairings which have the closest to even odds. We can find out what level of bias would be required to switch the directionality of the odds (or at least erase the tendency for one die to roll higher than the other). Lets try looking at Magenta and Red, which under the fair dice assumption have odds p(Magenta > Red)=5/9. What kind of bias will change this relationship? The odds can be evened out by either Magenta rolling ones more often, or red rolling nine more often. The question is then, how much bias would there need to in the dice in order to even out the odds between Magenta and Red?
Lets start with Red biasing toward rolling nine more often (recall that nine appears on only one face). Under the fair dice hypothesis, Red can roll nine (1/6 of the time) and win no matter what Magenta rolls, or by rolling four (5/6 of the time) and win when Magenta rolls one (1/3 of the time).
P(Red > Magenta) = 1/6 + 5/6 * 1/3, which is 4/9.
If we set this probability equal to 1/2, and replace the fraction of times that Red rolls nine with x, we can solve for the frequency needed to even the odds.
x + 5/6 * 1/3 = 1/2
x = 2/9
Meaning that the Red die would have to be biased toward rolling nine with 2/9 odds. That’s equivalent to rolling a nine 1 and 1/3 times (33%) more often than you would expect if the die were fair!
Alternatively, the other way the odds between Red and Magenta could be evened is if Magenta biased towards rolling ones more often. We can do the same kind of calculation as above to figure out how much bias would be needed.
1/6 + 5/6 * x = 1/2
x = 2/5
Which corresponds to Magenta having a 20% bias toward rolling ones. Of course, some combination of these biases could also be possible.
I leave it to the reader to work out the other pairings, but from the Red-Magenta analysis we can see that even if the dice deviated quite a bit from the expected 1/6 probability for each side, the edge afforded to Magenta is retained. I couldn’t find any convincing evidence for the extent of bias caused by pipping and rounded corners but it seems unlikely that it would be strong enough to change the structure of the game.




 to·di·dact n.
to·di·dact n. re, simul
re, simul


{kind=link}