I am currently working on a validation metric for binary prediction models. That is, models which make predictions about outcomes that can take on either of two possible states (eg Dead/not dead, heads/tails, cat in picture/no cat in picture, etc.) The most commonly used metric for this class of models is AUC, which assesses the relative error rates (false positive, false negative) across the whole range of possible decision thresholds. The result is a curve that looks something like this:
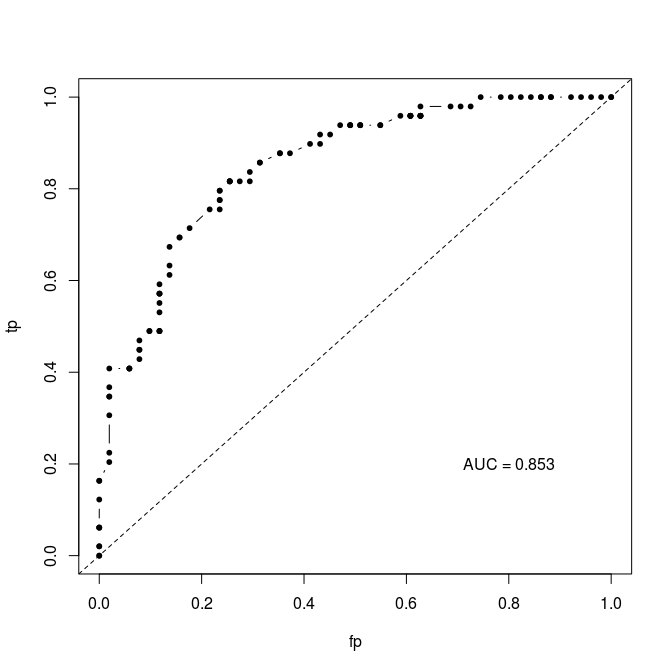
Where the area under the curve (the curve itself is the Receiver Operator Curve (ROC)) is some value between 0 and 1. The higher this value, the better your model is said to perform. The problem with this metric, as many authors have pointed out, is that a model can perform very well in terms of AUC, but be completely miscalibrated in terms of the actual probabilities placed on each outcome.
A model which distinguishes perfectly between positive and negative cases (AUC=1) by placing a probability of 0.01 on positive cases and 0.001 on negative cases may be very far off in terms of the actual probability of a positive case. For instance, positive cases may actually occur with probability 0.6 and negative cases with 0.2. In most real situations, our models will predict a whole range of different probabilities with a unique prediction for each data point, but the general idea remains. If your goal is simply to distinguish between cases, you may not care whether the probabilities are not correct. However, if your model is purporting to quantify risk then you very much want to know if you are placing the probabilistically true predictions on cases that are yet to be observed.
Which begs the question: What is probabilistic truth?
This questions appears, at least at first, to be rather simple. A frequentist definition would say that the probability is correct, or true, if the predicted probability is equal to the long run outcomes. Think of a dice rolled over and over counting the number of times a one is rolled. We would compare this frequency to our predicted probability of rolling a one (1/6 for a fair six-sided die) and would say that our predicted probability was true if this frequency matched 1/6.
But what about situations where we can’t re-run an experiment over and over again? How then would we evaluate the probabilistic truth of our predictions?
I’ll be working through this problem in a series of posts in the coming weeks. Stay tuned!

Let T be the Threshold used and x(1) … x(m) and y(1) … y(n) the values for the prediction function of the dependent variable that can take the two values x and y.
Suppose x(1)<.. <x(m-1)<T<x(m)<y(1)< .. <y(n), then AUC=1 but the prediction is not perfect. So yes, a perfect model has AUC=1 but not the other way around. Thus I wonder why we do not use RMSE or OOB that attain 100% only when the prediction is perfect.
Reblogged this on Easy ML World.
You might be interested in the graphical display in
Tjur, T. (2009) “Coefficients of determination in logistic regression models—A new proposal: The coefficient of discrimination.” The American Statistician vol. 63: 366-372.
http://dx.doi.org/10.1198/tast.2009.08210
This is basically a graphical version of the Hosmer–Lemeshow test. You can use the binomTools R package the plot, run test HL test and calculate Tjur’s coefficient of determination.
Pingback: What is probabilistic truth? Part 2 – Everything is conditional | bayesianbiologist
Pingback: How likely is the NSA PRISM program to catch a terrorist? | bayesianbiologist
Pingback: worth answering | my own private radio