A friend of mine just alerted me to a story on NPR describing a prize on offer from Warren Buffett and Quicken Loans. The prize is a billion dollars (1B USD) for correctly predicting all 63 games in the men’s Division I college basketball tournament this March. The facebook page announcing the contest puts the odds at 1:9,223,372,036,854,775,808, which they note “may vary depending upon the knowledge and skill of entrant”.
Being curious, I thought I’d see what the assumptions were that went into that number. It would make sense to start with the assumption that you don’t know a lick about college basketball and you just guess using a coin flip for every match-up. In this scenario you’re pretty bad, but you are no worse than random. If we take this assumption, we can calculate the odds as 1/(0.5)^63. To get precision down to a whole integer I pulled out trusty bc for the heavy lifting:
$ echo "scale=50; 1/(0.5^63)" | bc
9223372036854775808.000000
Well, that was easy. So if you were to just guess randomly, your odds of winning the big prize would be those published on the contest page. We can easily calculate the expected value of entering the contest as P(win)*prize, or 9,223,372,036ths of a dollar (that’s 9 nano dollars, if you’re paying attention). You’ve literally already spent that (and then some) in opportunity cost sunk into the time you are spending thinking about this contest and reading this post (but read on, ’cause it’s fun!).
But of course, you’re cleverer than that. You know everything about college basketball – or more likely if you are reading this blog – you have a kickass predictive model that is going to up your game and get your hands into the pocket of the Oracle from Omaha.
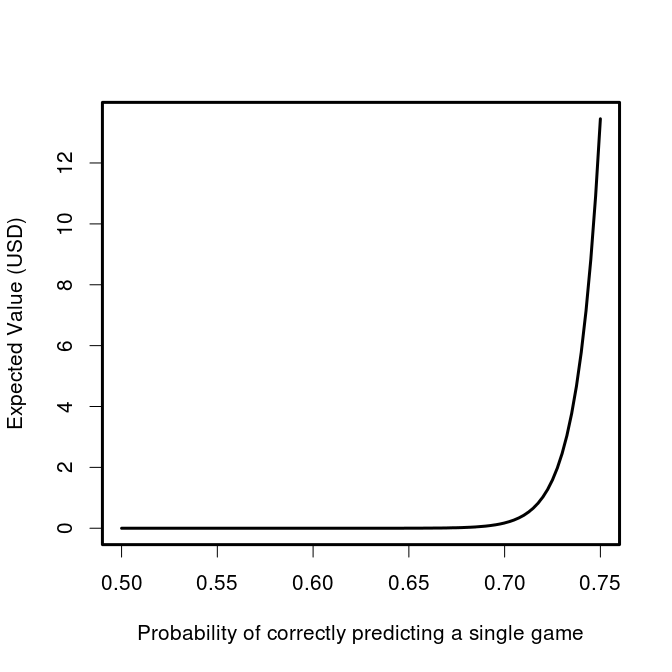
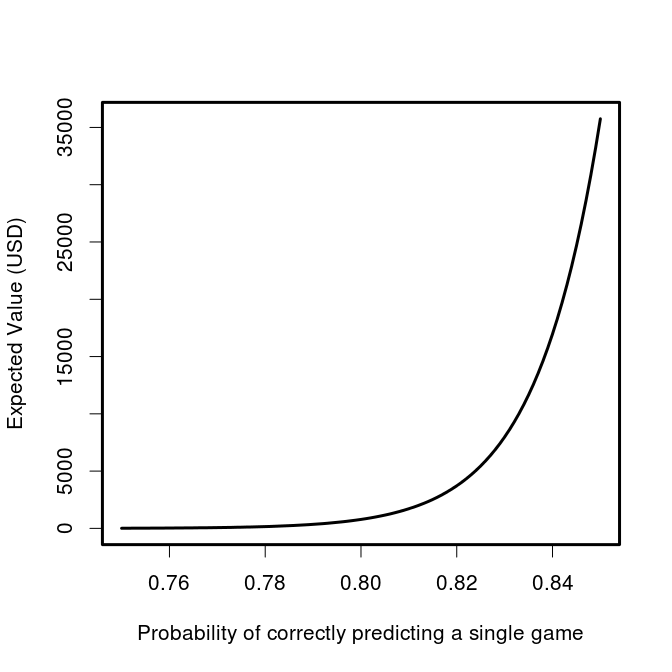
What level of predictiveness would you need to make this bet worth while? Let’s have a look at the expected value as a function of our individual game probability of being correct.

And if you think that you’re really good, we can look at the 0.75 to 0.85 range:

So it’s starting to look enticing, you might even be willing to take off work for a while if you thought you could get your model up to a consistent 85% correct game predictions, giving you an expected return of ~$35,000. A recent paper found that even after observing the first 40 scoring events, the outcome of NBA games is only predictable at 80%. In order to be eligible to win, you’ve obviously got to submit your picks before the playoff games begin, but even at this herculean level of accuracy, the expected value of an entry in the contest plummets down to $785.
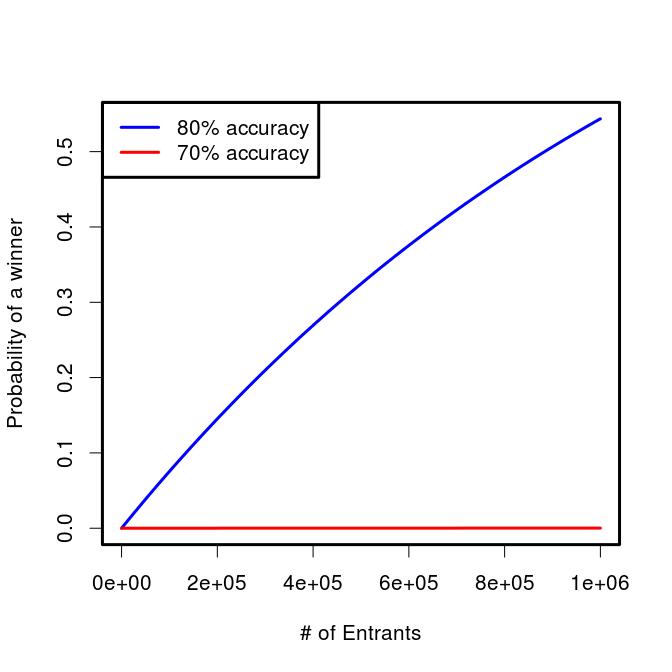
Those are the odds for an individual entrant, but what are the chances that Buffet and co will have to pay out? That, of course, depends on the number of entrants. Lets assume that the skill of all entrants is the same, though they all have unique models which make different predictions. In this case we can get the probability of at least one of them hitting it big. It will be the complement of no one winning. We already know the odds for a single entrant with a given level of accuracy, so we can just take the probability that each one doesn’t win, then take 1 minus that value.

Just as we saw that the expected value is very sensitive to the predictive accuracy of the participant, so too is the probability that the prize will be awarded at all. If 1 million super talented sporting sages with 80% game-level accuracy enter the contest, there will only be a slightly greater than 50% chance of anyone actually winning. If we substitute in a more reasonable (but let’s face it, still wildly high) figure for participants’ accuracy of 70%, the chance becomes only 1 in 5739 (0.017%) that the top prize will even be awarded even with a 1 million strong entrant pool.
tl;dr You’re not going to win, but you’re still going to play.
If you want to reproduce the numbers and plots in this post, check out this gist.