Editor’s note: This is a guest post by Marianne Corvellec from Plotly. This post is based on an interactive Notebook (click to view) she presented at the R User Conference on July 1st, 2014.
Plotly is a platform for making, editing, and sharing graphs. If you are used to making plots with ggplot2, you can call ggplotly() to make your plots interactive, web-based, and collaborative. For example, see plot.ly/~ggplot2examples/211, shown below and in this Notebook. Notice the hover text!

0. Get started
Visit http://plot.ly. Here, you’ll find a GUI that lets you create graphs from data you enter manually, or upload as a spreadsheet (or CSV file). From there you can edit graphs! Change between types (from bar charts to scatter charts), change colors and formatting, add fits and annotations, try other themes…

Our R API lets you use Plotly with R. Once you have your R visualization in Plotly, you can use the web interface to edit it, or to extract its data. Install and load package “plotly” in your favourite R environment. For a quick start, follow: https://plot.ly/ggplot2/getting-started/
Go social! Like, share, comment, fork and edit plots… Export them, embed them in your website. Collaboration has never been so sweet!

Not ready to publish? Set detailed permissions for who can view and who can edit your project.

1. Make a (static) plot with ggplot2
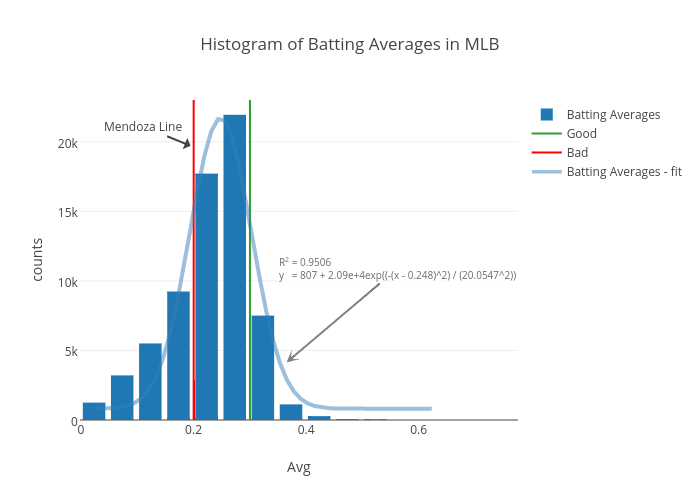
Baseball data is the best! Let’s plot a histogram of batting averages. I downloaded data here.
Load the CSV file of interest, take a look at the data, subset at will:
library(RCurl)
online_data <-
getURL("https://raw.githubusercontent.com/mkcor/baseball-notebook/master/Batting.csv")
batting_table <-
read.csv(textConnection(online_data))
head(batting_table)
summary(batting_table)
batting_table <-
subset(batting_table, yearID >= 2004)
The batting average is defined by the number of hits divided by at bats:
batting_table$Avg <-
with(batting_table, H / AB)
You may want to explore the distribution of your new variable as follows:
library(ggplot2)
ggplot(data=batting_table)
+ geom_histogram(aes(Avg), binwidth=0.05)
# Let's filter out entries where players were at bat less than 10 times.
batting_table <-
subset(batting_table, AB >= 10)
hist <-
ggplot(data=batting_table) + geom_histogram(aes(Avg),
binwidth=0.05)
hist
We have created a basic histogram; let us share it, so we can get input from others!
2. Save your R plot to plot.ly
# Install the latest version
# of the “plotly” package and load it
library(devtools)
install_github("ropensci/plotly")
library(plotly)
# Open a Plotly connection
py <-
plotly("ggplot2examples", "3gazttckd7")
Use your own credentials if you prefer. You can sign up for a Plotly account online.
Now call the `ggplotly()` method:
collab_hist <-
py$ggplotly(hist)
And boom!

You get a nice interactive version of your plot! Go ahead and hover…
Your plot lives at this URL (`collab_hist$response$url`) alongside the data. How great is that?!
If you wanted to keep your project private, you would use your own credentials and specify:
py <- plotly()
py$ggplotly(hist,
kwargs=list(filename="private_project",
world_readable=FALSE))
3. Edit your plot online
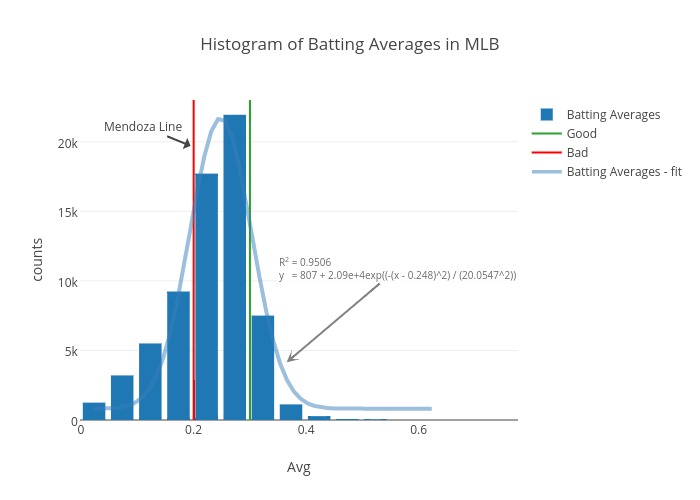
Now let us click “Fork and edit”. You (and whoever you’ve added as a collaborator) can make edits in the GUI. For instance, you can run a Gaussian fit on this distribution:

You can give a title, edit the legend, add notes, etc.

You can add annotations in a very flexible way, controlling what the arrow and text look like:

When you’re happy with the changes, click “Share” to get your plot’s URL.
If you append a supported extension to the URL, Plotly will translate your plot into that format. Use this to export static images, embed your graph as an iframe, or translate the code between languages. Supported file types include:
Isn’t life wonderful?
4. Retrieve your plot.ly plot in R
The JSON file specifies your plot completely (it contains all the data and layout info). You can view it as your plot’s DNA. The R file (https://plot.ly/~mkcor/305.r) is a conversion of this JSON into a nested list in R. So we can interact with it by programming in R!
Access a plot which lives on plot.ly with the well-named method `get_figure()`:
enhanc_hist <-
py$get_figure("mkcor", 305)
Take a look:
str(enhanc_hist)
# Data for second trace
enhanc_hist$data[[2]]
The second trace is a vertical line at 0.300 named “Good”. Say we get more ambitious and we want to show a vertical line at 0.350 named “Very Good”. We overwrite old values with our new values:
enhanc_hist$data[[2]]$name <- "VeryGood"
enhanc_hist$data[[2]]$x[[1]] <- 0.35
enhanc_hist$data[[2]]$x[[2]] <- 0.35
Send this new plot back to plot.ly!
enhanc_hist2 <-
py$plotly(enhanc_hist$data,
kwargs=list(layout=enhanc_hist$layout))
enhanc_hist2$url
Visit the above URL (`enhanc_hist2$url`).
How do you like this workflow? Let us know!
Tutorials are at plot.ly/learn. You can see more examples and documentatation at plot.ly/ggplot2 and plot.ly/r. Our gallery has the following examples:

Acknowledgments
This presentation benefited tremendously from comments by Matt Sundquist and Xavier Saint-Mleux.
Plotly’s R API is part of rOpenSci. It is under active development; you can find it on GitHub. Your thoughts, issues, and pull requests are always welcome!







{kind=link}
{kind=link}
{kind=link}