The Annual Conference on Neural Information Processing Systems (NIPS) has recently listed this year’s accepted papers. There are 403 paper titles listed, which made for great morning coffee reading, trying to pick out the ones that most interest me.
Being a machine learning conference, it’s only reasonable that we apply a little machine learning to this (decidedly _small_) data.
Building off of the great example code in a post by Jordan Barber on Latent Dirichlet Allocation (LDA) with Python, I scraped the paper titles and built an LDA topic model with 5 topics. All of the code to reproduce this post is available on github. Here are the top 10 most probable words from each of the derived topics:
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | learning | learning | optimization | learning | via |
| 1 | models | inference | networks | bayesian | models |
| 2 | neural | sparse | time | sample | inference |
| 3 | high | models | stochastic | analysis | networks |
| 4 | stochastic | non | model | data | deep |
| 5 | dimensional | optimization | convex | inference | learning |
| 6 | networks | algorithms | monte | spectral | fast |
| 7 | graphs | multi | carlo | networks | variational |
| 8 | optimal | linear | neural | bandits | neural |
| 9 | sampling | convergence | information | methods | convolutional |
Normally, we might try to attach some kind of label to each topic using our beefy human brains and subject matter expertise, but I didn’t bother with this — nothing too obvious stuck out at me. If you think that you have appropriate names for them feel free to let me know. Given that we are only working with the titles (no abstracts or full paper text), I think that there aren’t obvious human-interpretable topics jumping out. But let’s not let that stop us from proceeding.
We can also represent the inferred topics with the much maligned, but handy-dandy wordcloud visualization:




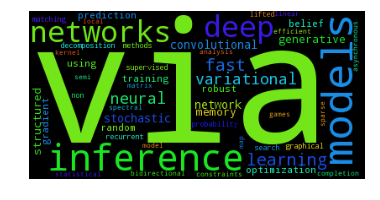
Since we are modeling the paper title generating process as a probability distribution of topics, each of which is a probability distribution of words, we can use this generating process to suggest keywords for each title. These keywords may or may not show up in the title itself. Here are some from the first 10 titles:
================ Double or Nothing: Multiplicative Incentive Mechanisms for Crowdsourcing Generated Keywords: [u'iteration', u'inference', u'theory'] ================ Learning with Symmetric Label Noise: The Importance of Being Unhinged Generated Keywords: [u'uncertainty', u'randomized', u'neural'] ================ Algorithmic Stability and Uniform Generalization Generated Keywords: [u'spatial', u'robust', u'dimensional'] ================ Adaptive Low-Complexity Sequential Inference for Dirichlet Process Mixture Models Generated Keywords: [u'rates', u'fast', u'based'] ================ Covariance-Controlled Adaptive Langevin Thermostat for Large-Scale Bayesian Sampling Generated Keywords: [u'monte', u'neural', u'stochastic'] ================ Robust Portfolio Optimization Generated Keywords: [u'learning', u'online', u'matrix'] ================ Logarithmic Time Online Multiclass prediction Generated Keywords: [u'complexity', u'problems', u'stein'] ================ Planar Ultrametric Rounding for Image Segmentation Generated Keywords: [u'deep', u'graphs', u'neural'] ================ Expressing an Image Stream with a Sequence of Natural Sentences Generated Keywords: [u'latent', u'process', u'stochastic'] ================ Parallel Correlation Clustering on Big Graphs Generated Keywords: [u'robust', u'learning', u'learning']
Entropy and the most “interdisciplinary” paper title
While some titles are strongly associated with a single topic, others seem to be generated from more even distributions over topics than others. Paper titles with more equal representation over topics could be considered to be, in some way, more interdisciplinary, or at least, intertopicular (yes, I just made that word up). To find these papers, we’ll find which paper titles have the highest information entropy in their inferred topic distribution.
Here are the top 10 along with their associated entropies:
So it looks like by this method, the ‘Where are they looking’ has the highest entropy as a result of topic uncertainty, more than any real multi-topic content.
