The theme for this year’s workshop will be “Moving beyond supervised learning in healthcare”. This will be a great forum for those who work on computational solutions to the challenges facing clinical medicine. The submission deadline is Friday Oct 26, 2018. Hope to see you there!
Tag Archives: NIPS
NIPS 2017 Summary
Some (opinionated) themes and highlights from this year’s NIPS conference:
Generative Adversarial Networks are the hotness at NIPS 2016
While they hit the scene two years ago, Generative Adversarial Networks (GANs) have become the darlings of this year’s NIPS conference. The term “Generative Adversarial” appears 170 times in the conference program. So far I’ve seen talks demonstrating their utility in everything from generating realistic images, predicting and filling in missing video segments, rooms, maps, and objects of various sorts. They are even being applied to the world of high energy particle physics, pushing the state of the art of inference within the language of quantum field theory.
The basic idea is to build two models and to pit them against each other (hence the adversarial part). The generative model takes random inputs and tries to generate output data that “look like” real data. The discriminative model takes as input data from both the generative model and real data and tries to correctly distinguish between them. By updating each model in turn iteratively, we hope to reach an equilibrium where neither the discriminator nor the generator can improve. At this point the generator is doing it’s best to fool the discriminator, and the discriminator is doing it’s best not to be fooled. The result (if everything goes well) is a generative model which, given some random inputs, will output data which appears to be a plausible sample from your dataset (eg cat faces).
As with any concept that I’m trying to wrap my head around, I took a moment to create a toy example of a GAN to try to get a feel for what is going on.
Let’s start with a simple distribution from which to draw our “real” data from.
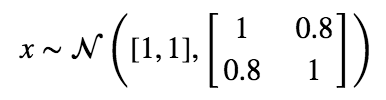
Next, we’ll create our generator and discriminator networks using tensorflow. Each will be a three layer, fully connected network with relu’s in the hidden layers. The loss function for the generative model is -1(loss function of discriminative). This is the adversarial part. The generator does better as the discriminator does worse. I’ve put the code for building this toy example here.
Next, we’ll fit each model in turn. Note in the code that we gave each optimizer a list of variables to update via gradient descent. This is because we don’t want to update the weights of the discriminator while we’re updating the weights of the generator, and visa versa.
loss at step 0: discriminative: 11.650652, generative: -9.347455

loss at step 200: discriminative: 8.815780, generative: -9.117246

loss at step 400: discriminative: 8.826855, generative: -9.462300
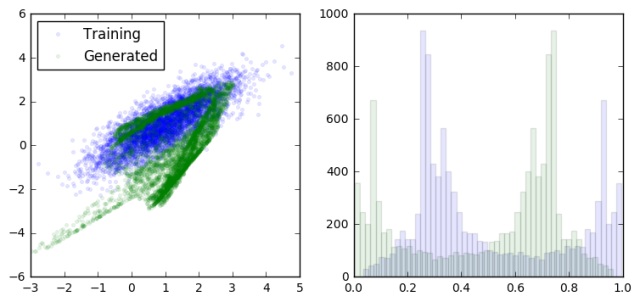
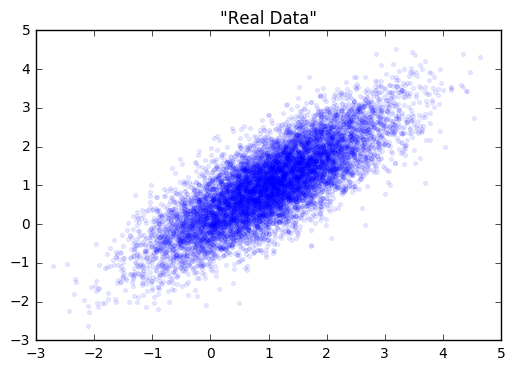
loss at step 600: discriminative: 8.893397, generative: -9.835464

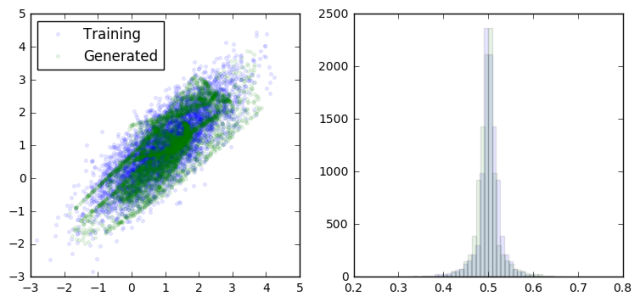
As we can see, the generator is learning to output data that looks more and more like a sample from the training data. At the same time, the discriminator is having a harder and harder dime telling them apart (as seen in the overlapping prediction histograms on the right).
Obviously this is a trivial example to put a GAN to work on, but when it comes to high-dimensional data with complex dependency structures, this approach starts to really shine. I’m sure the hotness of this approach won’t cool off any time soon.
All of the code for generating this GAN is available on github.
Categorizing NIPS papers using LDA topic modeling
The Annual Conference on Neural Information Processing Systems (NIPS) has recently listed this year’s accepted papers. There are 403 paper titles listed, which made for great morning coffee reading, trying to pick out the ones that most interest me.
Being a machine learning conference, it’s only reasonable that we apply a little machine learning to this (decidedly _small_) data.
Building off of the great example code in a post by Jordan Barber on Latent Dirichlet Allocation (LDA) with Python, I scraped the paper titles and built an LDA topic model with 5 topics. All of the code to reproduce this post is available on github. Here are the top 10 most probable words from each of the derived topics:
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | learning | learning | optimization | learning | via |
| 1 | models | inference | networks | bayesian | models |
| 2 | neural | sparse | time | sample | inference |
| 3 | high | models | stochastic | analysis | networks |
| 4 | stochastic | non | model | data | deep |
| 5 | dimensional | optimization | convex | inference | learning |
| 6 | networks | algorithms | monte | spectral | fast |
| 7 | graphs | multi | carlo | networks | variational |
| 8 | optimal | linear | neural | bandits | neural |
| 9 | sampling | convergence | information | methods | convolutional |
Normally, we might try to attach some kind of label to each topic using our beefy human brains and subject matter expertise, but I didn’t bother with this — nothing too obvious stuck out at me. If you think that you have appropriate names for them feel free to let me know. Given that we are only working with the titles (no abstracts or full paper text), I think that there aren’t obvious human-interpretable topics jumping out. But let’s not let that stop us from proceeding.
We can also represent the inferred topics with the much maligned, but handy-dandy wordcloud visualization:




Since we are modeling the paper title generating process as a probability distribution of topics, each of which is a probability distribution of words, we can use this generating process to suggest keywords for each title. These keywords may or may not show up in the title itself. Here are some from the first 10 titles:
================ Double or Nothing: Multiplicative Incentive Mechanisms for Crowdsourcing Generated Keywords: [u'iteration', u'inference', u'theory'] ================ Learning with Symmetric Label Noise: The Importance of Being Unhinged Generated Keywords: [u'uncertainty', u'randomized', u'neural'] ================ Algorithmic Stability and Uniform Generalization Generated Keywords: [u'spatial', u'robust', u'dimensional'] ================ Adaptive Low-Complexity Sequential Inference for Dirichlet Process Mixture Models Generated Keywords: [u'rates', u'fast', u'based'] ================ Covariance-Controlled Adaptive Langevin Thermostat for Large-Scale Bayesian Sampling Generated Keywords: [u'monte', u'neural', u'stochastic'] ================ Robust Portfolio Optimization Generated Keywords: [u'learning', u'online', u'matrix'] ================ Logarithmic Time Online Multiclass prediction Generated Keywords: [u'complexity', u'problems', u'stein'] ================ Planar Ultrametric Rounding for Image Segmentation Generated Keywords: [u'deep', u'graphs', u'neural'] ================ Expressing an Image Stream with a Sequence of Natural Sentences Generated Keywords: [u'latent', u'process', u'stochastic'] ================ Parallel Correlation Clustering on Big Graphs Generated Keywords: [u'robust', u'learning', u'learning']
Entropy and the most “interdisciplinary” paper title
While some titles are strongly associated with a single topic, others seem to be generated from more even distributions over topics than others. Paper titles with more equal representation over topics could be considered to be, in some way, more interdisciplinary, or at least, intertopicular (yes, I just made that word up). To find these papers, we’ll find which paper titles have the highest information entropy in their inferred topic distribution.
Here are the top 10 along with their associated entropies:
So it looks like by this method, the ‘Where are they looking’ has the highest entropy as a result of topic uncertainty, more than any real multi-topic content.
