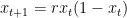*Edit: I made a video!
Dispersal is a key process in many domains, and particularly in ecology. Individuals move in space, and this movement can be modelled as a random process following some kernel. The dispersal kernel is simply a probability distribution describing the distance travelled in a given time frame. Since space is continuous, it is natural to use a continuous kernel. However, some modelling frameworks are formulated on a lattice, or discrete array of patches.
So how can we implement a continuous kernel in discrete space?
As with many modelling situations, we could approach this in a number of ways. Here is the implementation that I can up with, and I welcome your suggestions, dear reader, for alternatives or improvements to this approach.
- Draw a random variate d from the dispersal kernel.
- Draw a uniform random number θ between 0 and 2π, which we will use to choose a direction.
- Calculate the relative location (in continuous space) of the dispersed individuals using some trig:
x = cos(θ) d
y = sin(θ) d - Determine the new location on the lattice for each individual by adding the relative x and y positions to the current location. Round these locations to the nearest integer and take the modulo of this integer and the lattice size. This creates a torus out of the lattice such that the outer edges loop back on each other. If you remember the old Donkey Kong games, you can think of this like how when you leave out the right side of the screen you enter from the left.
I implemented this approach in R as a function that takes in a population in a lattice, and returns a lattice with the dispersed population. The user can also specify which dispersal kernel to use. Here is the result using a negative-exponential kernel on a 50×50 lattice.

Created by iterating over the dispersal function:
## General function to take in a lattice and disperse
## according to a user provided dispersal kernel
## Author: Corey Chivers
lat_disp<-function(pop,kernel,...)
{
lattice_size<-dim(pop)
new_pop<-array(0,dim=lattice_size)
for(i in 1:lattice_size[1])
{
for(j in 1:lattice_size[2])
{
N<-pop[i,j]
dist<-kernel(N,...)
theta<-runif(N,0,2*pi)
x<-cos(theta)*dist
y<-sin(theta)*dist
for(k in 1:N)
{
x_ind<-(round(i+x[k])-1) %% lattice_size[1] + 1
y_ind<-(round(j+y[k])-1) %% lattice_size[2] + 1
new_pop[x_ind,y_ind]<-new_pop[x_ind,y_ind]+1
}
}
}
return(new_pop)
}
For comparison, I also ran the same population using a Gaussian kernel. I defined the parameters of both kernels to have a mean dispersal distance of 1.
Here is the result using a Gaussian kernel:

The resulting population after 35 time steps has a smaller range than when using the exponential kernel, highlighting the importance of the shape of the dispersal kernel for spreading populations (remember that in both cases the average dispersal distance is the same).
Code for generating the plots:
############## Run and plot #######################
## Custom colour ramp
colours<-c('grey','blue','black')
cus_col<-colorRampPalette(colors=colours, space = c("rgb", "Lab"),interpolate = c("linear", "spline"))
## Initialize population array
Time=35
pop<-array(0,dim=c(Time,50,50))
pop[1,25,25]<-10000
### Normal Kernel ###
par(mfrow=c(1,1))
for(i in 2:Time)
{
image(pop[i-1,,],col=cus_col(100),xaxt='n',yaxt='n')
pop[i,,]<-lat_disp(pop[i-1,,],kernel=rnorm,mean=0,sd=1)
}
## Plot
png('normal_kern.png', width = 800, height = 800)
par(mfrow=c(2,2),pty='s',omi=c(0.1,0.1,0.5,0.1),mar=c(2,0,2,0))
times<-c(5,15,25,35)
for(i in times)
image(pop[i-1,,],
col=cus_col(100),
xaxt='n',
yaxt='n',
useRaster=TRUE,
main=paste("Time =",i))
mtext("Gaussian Kernel",outer=TRUE,cex=1.5)
dev.off()
### Exponential Kernel ###
par(mfrow=c(1,1))
for(i in 2:Time)
{
image(pop[i-1,,],col=cus_col(100),xaxt='n',yaxt='n')
pop[i,,]<-lat_disp(pop[i-1,,],kernel=rexp,rate=1)
}
## Plot
png('exp_kern.png', width = 800, height = 800)
par(mfrow=c(2,2),pty='s',omi=c(0.1,0.1,0.5,0.1),mar=c(2,0,2,0))
times<-c(5,15,25,35)
for(i in times)
image(pop[i-1,,],
col=cus_col(100),
xaxt='n',
yaxt='n',
useRaster=TRUE,
main=paste("Time =",i))
mtext("Exponential Kernel",outer=TRUE,cex=1.5)
dev.off()
############################################################